I’m working on a Java component I’m calling Visual Expression Builder and have done an initial commit to github. The problem I’m trying to address is the limited user interface most applications present for allowing the user to build logical or mathematical expressions.
Now, I understand that most users are flummoxed by high school algebra, but you shouldn’t underestimate the capacity of users to doggedly move bits and pieces around until they work, even if they aren’t entirely sure how something works.
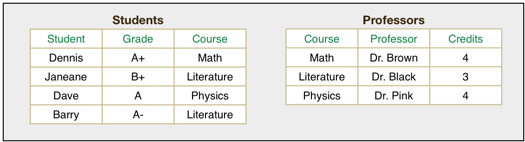
Case study: Address book Smart Groups
Here’s a typical example from Apple’s Address Book application:
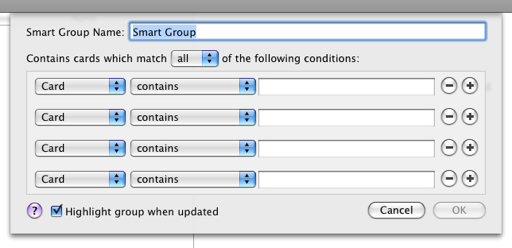
You can use the plus and minus buttons to add constraints and you can choose to match all or just one. It’s tremendously limited; you can’t even say “this and (that or those)”. The problem is that the form metaphor doesn’t scale structure well at all, and it’s a major limitation of all GUIs that are beholden to it.
But this is a good example of the task I’m trying to improve: letting the user build a simple expression, whether it’s criteria for a query or a calculated field or something related.
Case study: OpenOffice.org Function Wizard
Spreadsheets are a more advanced system than what I’m trying to handle. Here’s what OpenOffice’s function wizard looks like:
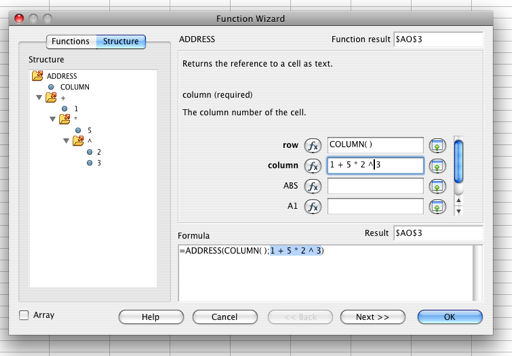
The Function Wizard is more geared towards helping a proficient user (probably an Excel user) migrate to OpenOffice. As such, the user is expected to know some basic concepts of functions, and probably only needs help in a few areas.
The structure diagram doesn’t explain why anything fits where it does and doesn’t allow for manipulation. The right pane is quite helpful in showing the parameters of the function in question. Also, due to its being geared to a proficient user, the function wizard doesn’t provide assistance with arithmetic. I had to guess that ^ was the exponent operator.
One poor assumption the designers make, I think, is that they don’t handle types very well. In the case of OpenOffice, they were building on the design decisions made twenty years ago with Microsoft Excel to use a “typeless” system, and it means that the system knows there’s a type and the user often needs to know there’s a type, but no one wants to admit it.
Case study: OpenOffice.org Query Designer

This is the Query Builder from OpenOffice and shows a very popular way of building an expression. This is optimized towards the common case where users have trouble with complex SQL constructs like grouping. One interesting facet of this is the criterion section. You get conjunction over different fields and disjunction over that, but you really can’t tell just by looking at it. It’s also quite hard to negate a section of the expression; you’d have to know DeMorgan’s law to do it. You also simply have to know that you can enter < 5 in the criteria, which is not a standard mathematical expression at all.
Case study: Circuit layout / network metaphors
On the really high-end there is the CAD software that allows a user to build components. You simply can’t beat actually designing a machine from wires and transistors for flexibility.
Assuming the interface was simplified to only handle basic mathematical expressions, such an interface still runs right into the WYSIWYG Productivity Sinkhole. Modern applications let us lay out documents to pixel perfect precision, and this is often a huge waste of time. Obviously, in some cases it’s worth it to make something look good, but I want users to be able to create an expression without worrying about exactly how it looks.
It’s very hard to allow a person to place components anywhere on the screen and avoid having to tediously move stuff around to no effect.
Proposal: The Puzzle Piece Metaphor
With that in mind, what I’m working on is what I call the puzzle piece metaphor. Nodes, which may be literals, arguments, operators or possibly other elements, are represented as puzzle pieces. The connection is represented as the little nibs that hook puzzle pieces together.
To keep things tidy, we bend the metaphor a bit and allow puzzle pieces to resize dynamically in width, like so:

I didn’t show the nibs in that diagram, but as you can see, the plus operator is wide enough to accommodate all its arguments. Also, the semantics for dragging are fairly straightforward since nibs fit together and pieces resize as necessary. In general, picking up an operator picks up all its precedents. This does mean that you can have separate groups doing separate things, and I may have a receptacle at the bottom of the canvas to set one group to be the official result. Allowing other groups enables the user to build a larger expression from smaller ones, and potentially allows for prefabricated templates. But because pieces fit together and resize automatically and predictably, there’s no messing around with the layout.
Here’s the layout diagram for an operator piece:

It’s pretty easy to generate Bézier paths using Java’s 2D package, and the squiggly puzzle piece lines are going to be fairly subtle so
Although I’m going to experiment with a few different layouts, my intuition is that a simple canvas and toolbox approach is best. An empty component might look like so:

I’ll be posting more on this, hopefully a timetable to get a test applet set up, or you can keep an eye on the github repository.